Jobs & resources¶
A trac platform deployment has access to four types of system resource. The technologies providing these services will vary by deployment, but the platform interacts with them the same way regardless.
Internal Storage |
Primary data storage to which the platform has sole write access. All analytical inputs and outputs are stored here using an append-only model. |
External Storage |
Storage locations that the platform is granted read or write access to, used for importing and exporting data. |
Code Repository |
External version control systems (e.g. GitHub, GitLab, Nexus) used to store the model code orchestrated on the platform. |
Compute Service |
The execution environment the platform can call upon to run jobs (e.g. Kubernetes, cloud batch services). |
With these resources, users with appropriate permissions can run five job types.
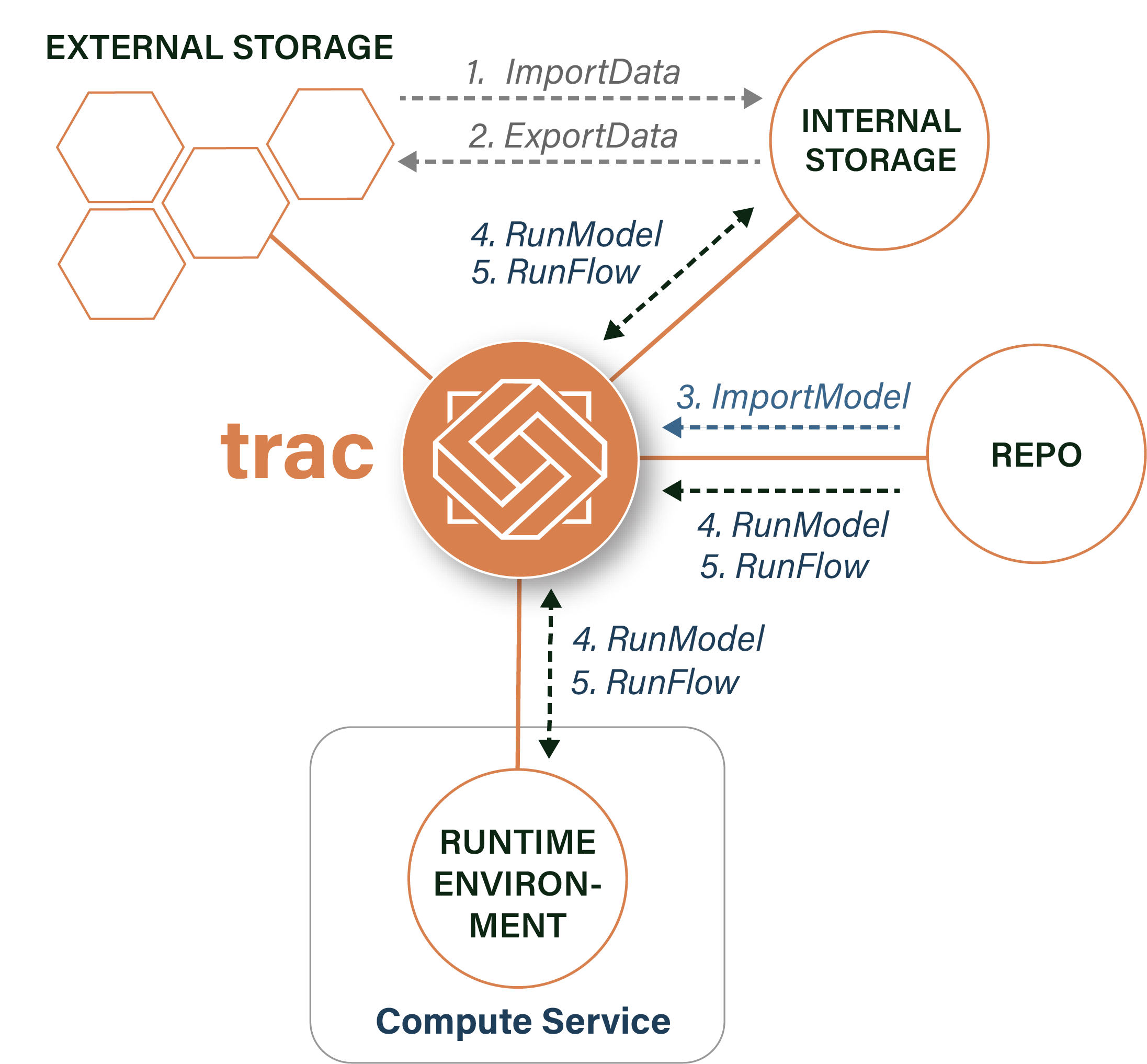
Operational jobs manage the movement of models and data onto and off the platform:
ImportModel |
Brings a new model or model version onto the platform from a code repository. |
ImportData |
Copies data from an external storage location into internal storage via a batch process. |
ExportData |
Publishes data from internal storage to an external storage location via a batch process. |
Calculation jobs execute analytical work using the compute service. Because all assets referenced in a calculation job — model code and input data — are stored immutably within the platform perimeter, the job definition is a self-contained calculation contract that can be reproduced exactly at any point in the future:
RunModel |
Executes a single model against a set of data and parameter inputs using the compute service. |
RunFlow |
Executes a chain of models (a flow) against a set of data, model, and parameter inputs. |
Note
Data, File, and Schema objects can be loaded directly via the UI, creating the object in the metadata store without a corresponding job record. Building a Flow also works this way.