Run a flow¶
Set up¶
Click ‘Run a Flow’ on the main menu or homepage to configure a RunFlow Job.
First, select the Flow you want to use…
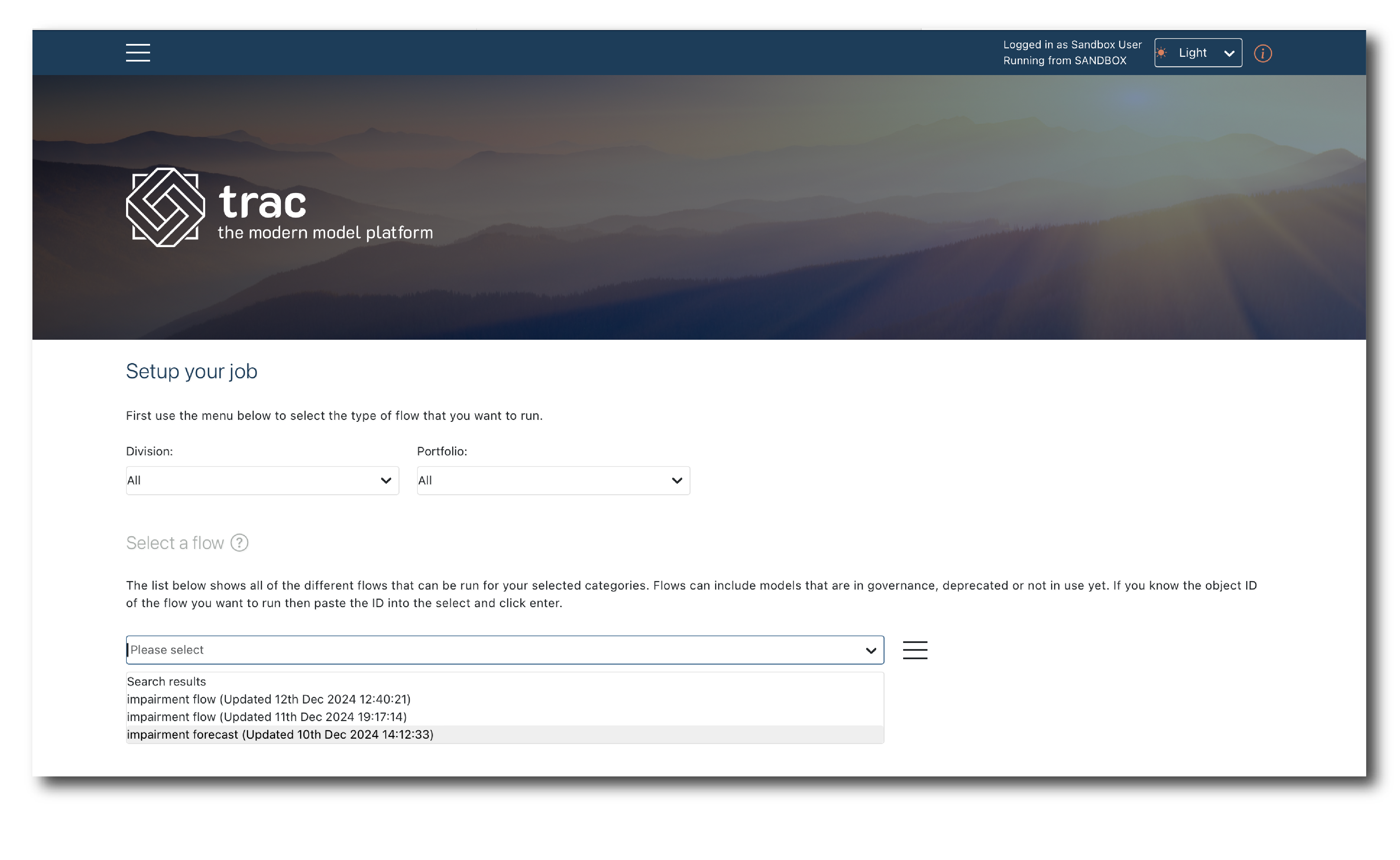
Clicking ‘Show chain’ expands a list of the Models which make up the Flow.
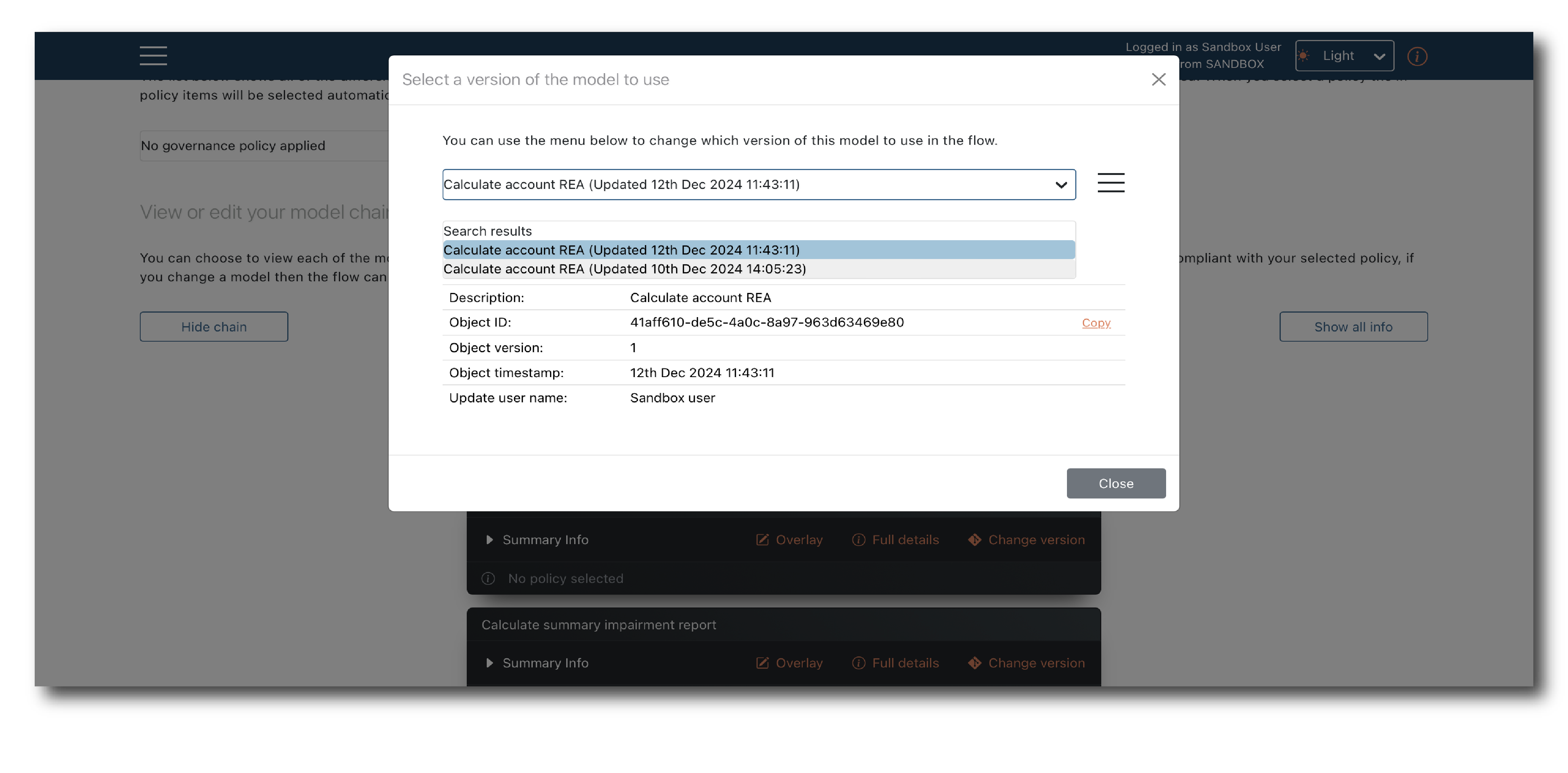
If more than one Model matches the criteria for use in the Flow, the most recent version is selected. This can be manually changed by clicking ‘Change version’.
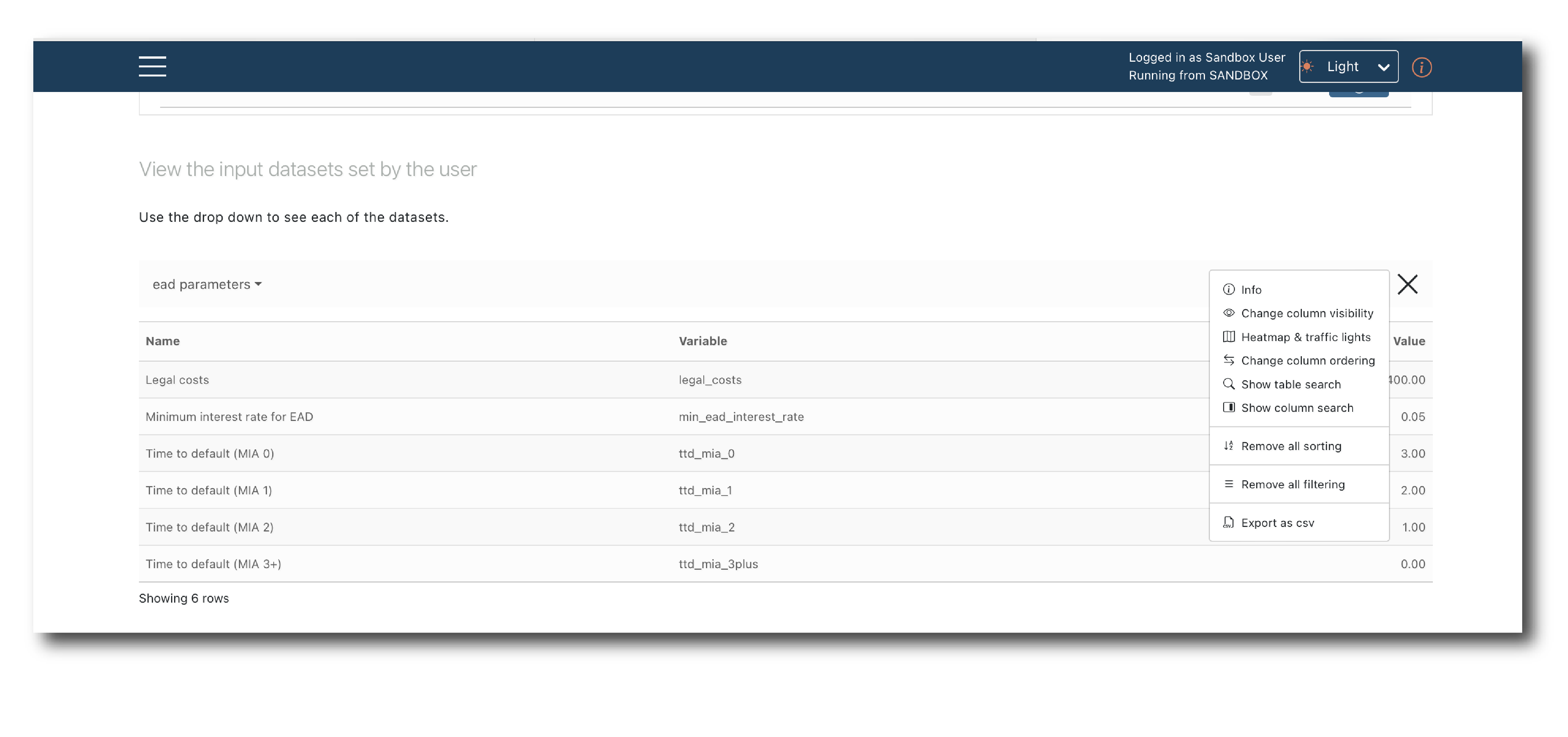
Below this the default values of any parameters are pre-populated, as are the data inputs.
If no suitable data is found you see an error message. If multiple options are found the most recent is selected but you can pick an alternate via the drop-down.
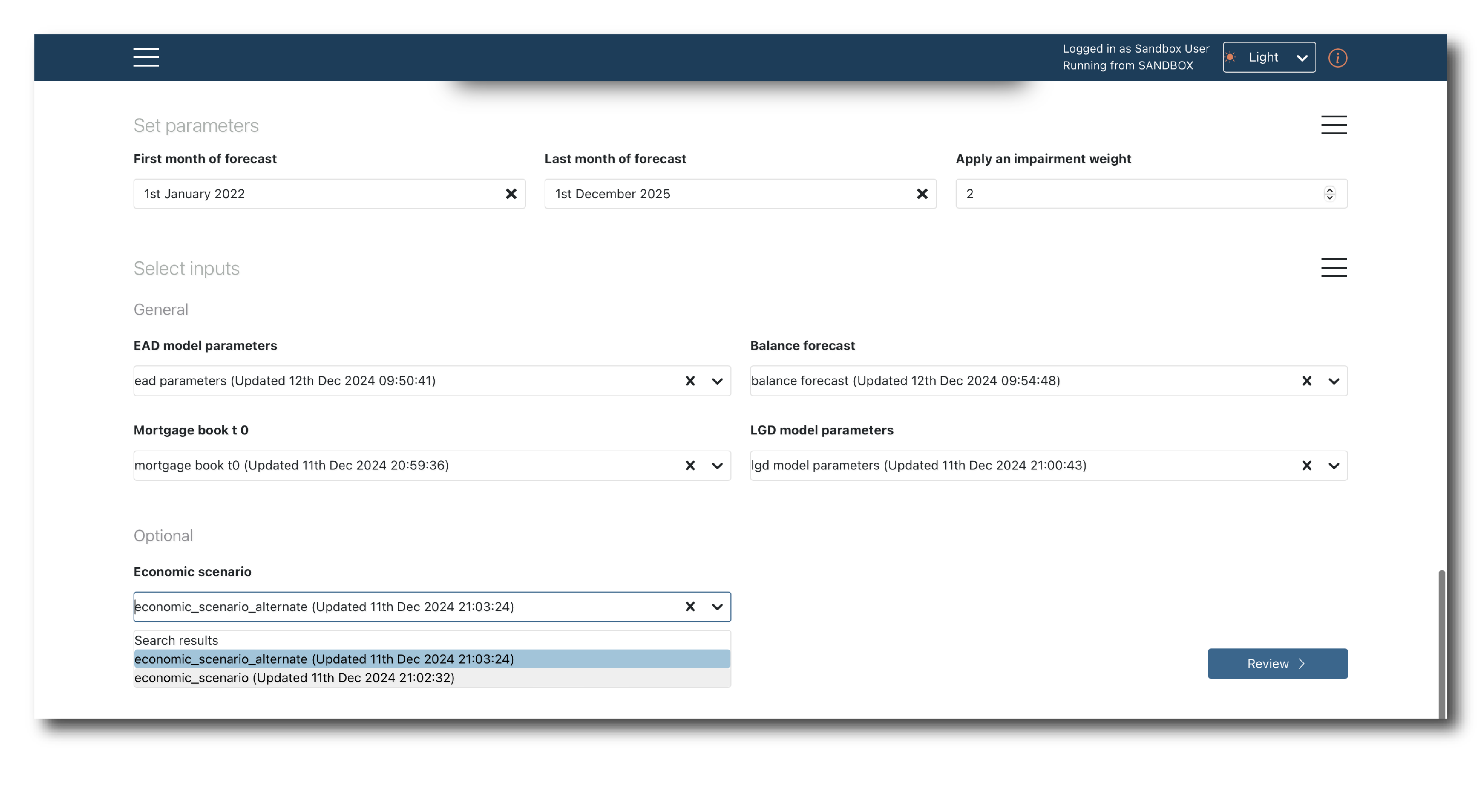
Once finished, click ‘Review’ to see a final breakdown of what will be in the Job.
Review & launch¶
Clicking ‘View full info’ brings up the full details of the Flow including visualisation
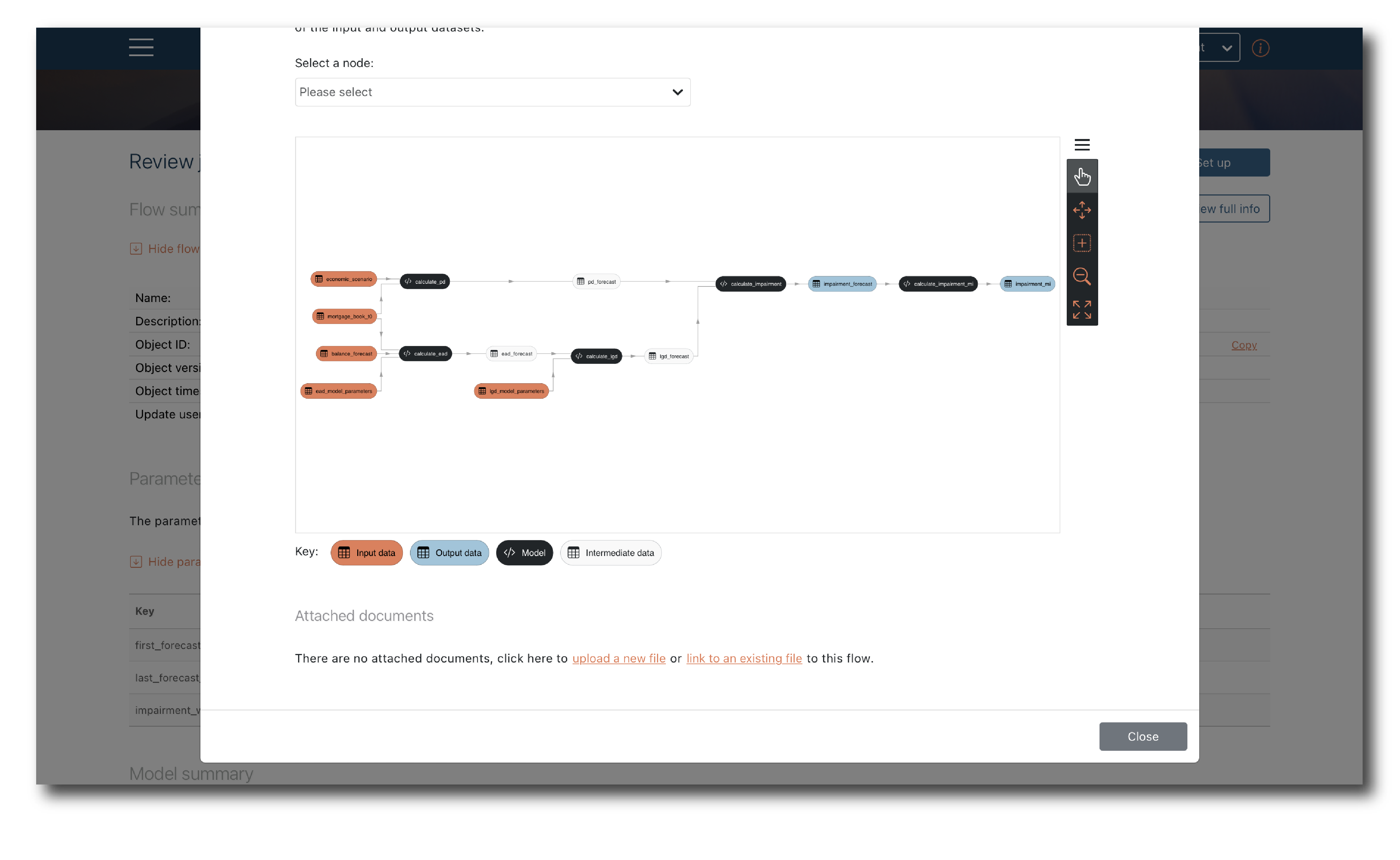
You can see object summaries for each Model and Data input via the ‘More info’ buttons.
If it all looks correct, populate the general attributes and click ‘Run’.
A Tag is not required but if populated, all the data outputs will have this Tag assigned, making them easier to find.
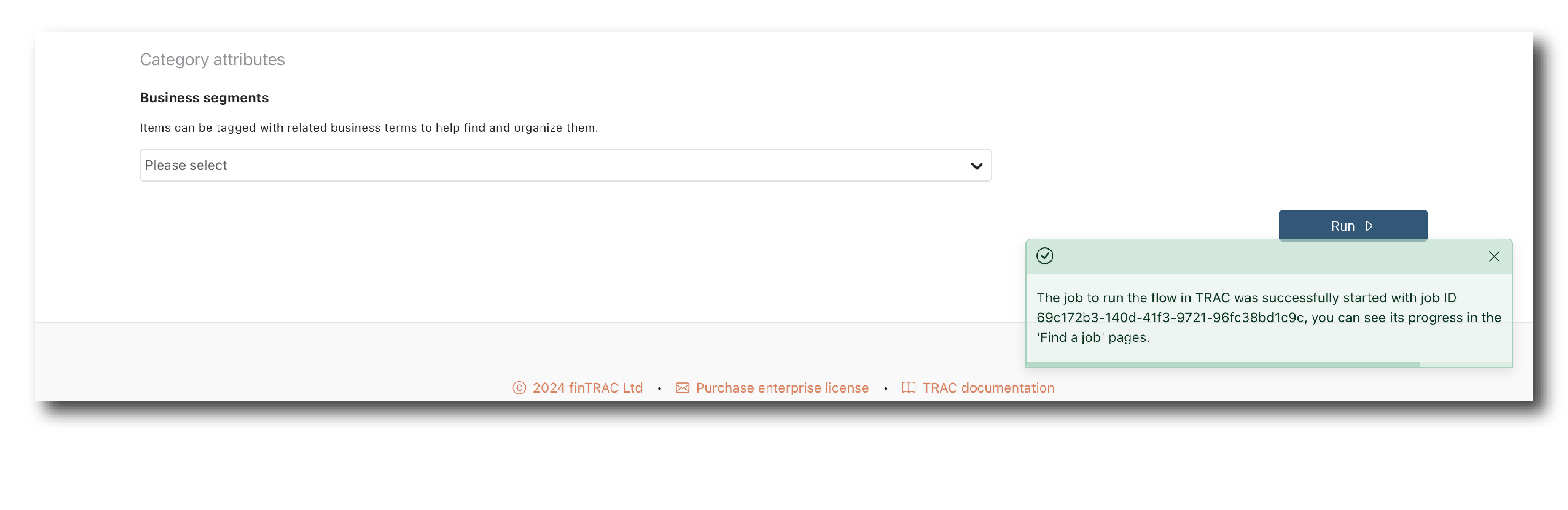
You will get a message telling you the job has started. It won’t tell you the outcome, so (find the job) to check its status.
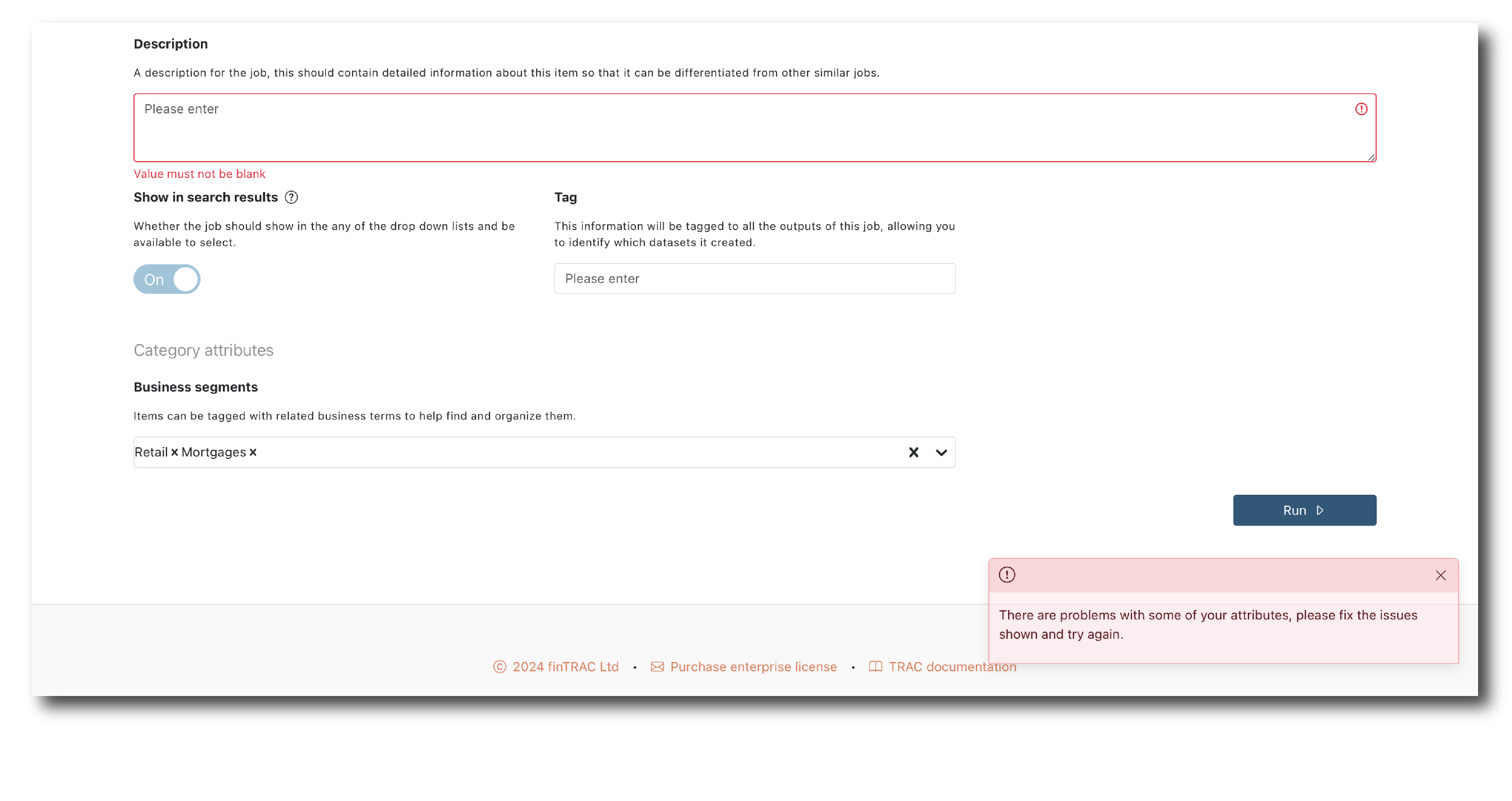
If there’s an issue with the Job set-up you will see a red message instead. The most common issues are missing attribute information or mis-aligned data schemas.
Schema validation¶
trac applies strict schema validation when compiling a Job. Key things to remember are:
It occurs between schemas, not between data content
It considers Field name, Field Type, Business key, Categorical and Not nullable
The order in which field names appear is not important
A source schema must contain all the fields needed by the target schema
The source schema can contain extra fields