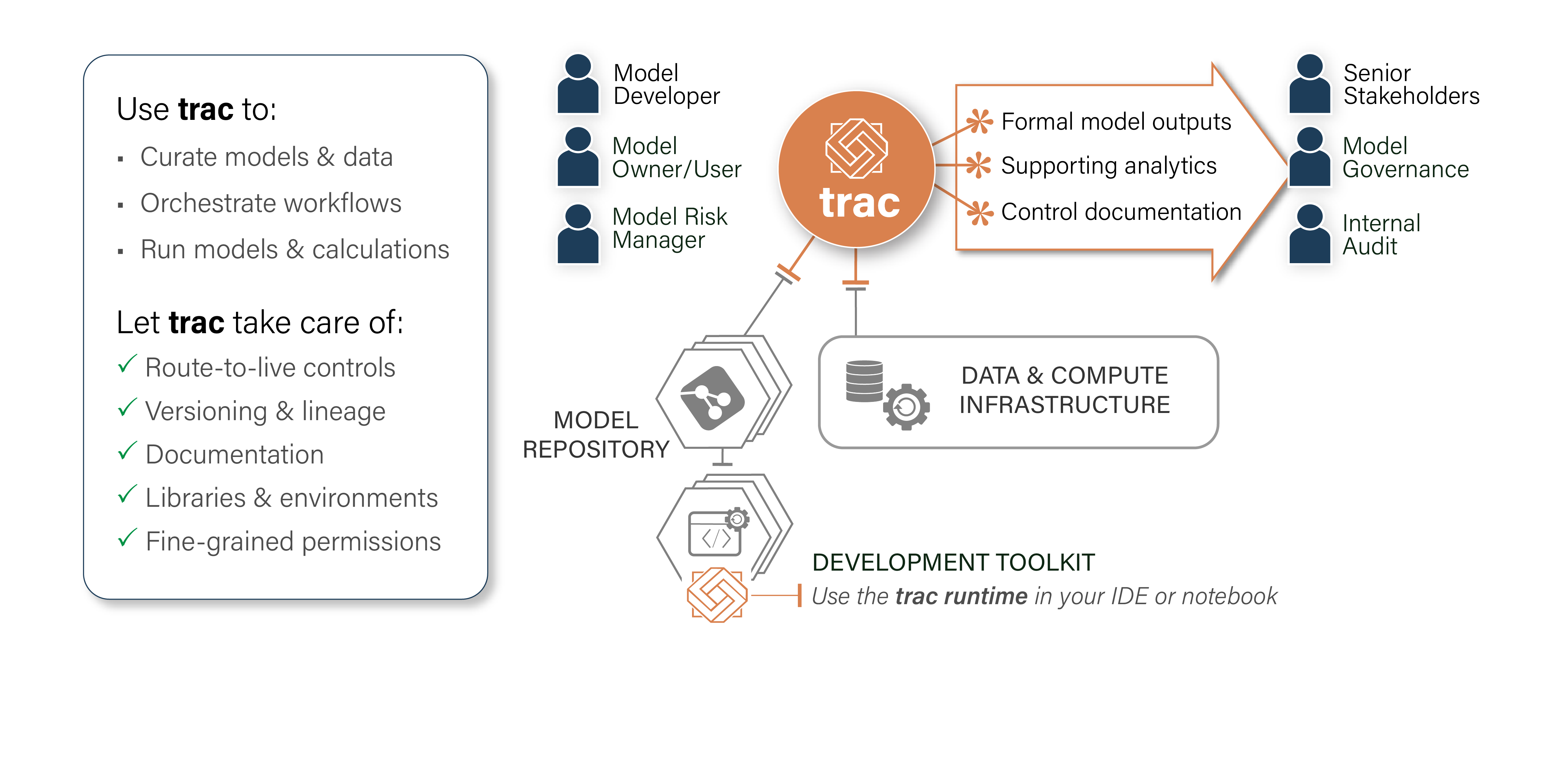
Functional design¶
Metadata model¶
Unlike traditional model platforms, trac is built around a structural metadata model which catalogues and describes everything on the platform. The model consists of two layers:
OBJECTS |
The model’s structural elements. Each object type (e.g. models or data) has its own metadata structure |
TAGS |
Used to index, describe and control objects. Some tags are controlled by the platform, some are user-defined |
Note
By recording object creation and tag modification actions in a time-consistent manner, trac builds a comprehensive audit history of the entire platform and its contents.
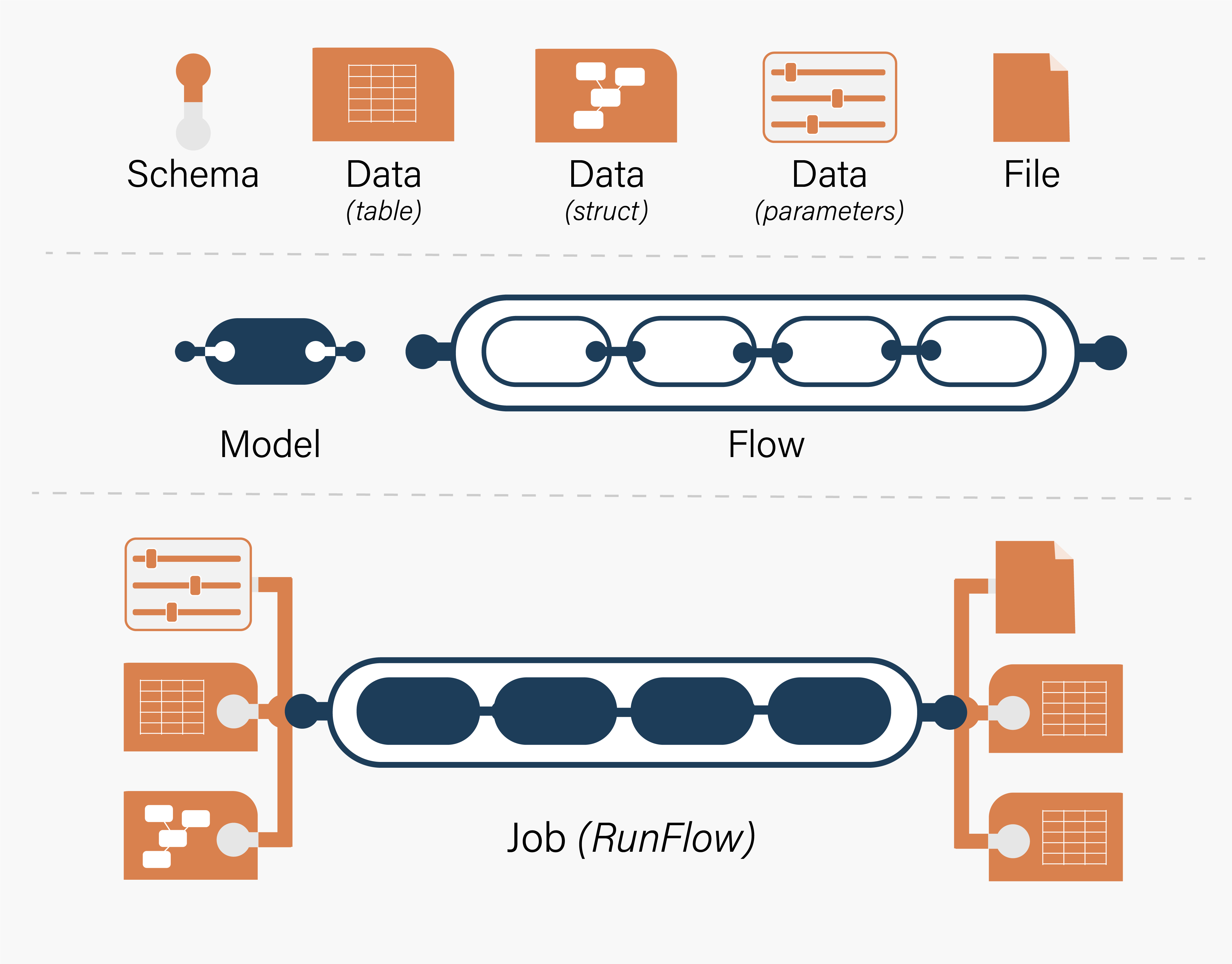
Objects¶
All processes on trac are constructed using a combination of six object types.
SCHEMA |
Defines the names, types, constraints, and relationships of fields in a Data object. Schema objects can be re-used across Data objects. Two sub-types are supported: Table and Structured (or ‘Struct’). |
DATA |
Collections of data records that are available for use on the platform. Data objects contain their schemas, stored either as part of the Data object definition or by mapping to a Schema object. |
MODEL |
Discrete units of code stored in a repository that have been made available for use on the platform. A Model metadata object refers to and describes a versioned unit of code stored in the repository. |
FLOW |
The blueprint of a complex calculation involving multiple models which trac can run on demand, represented as a graph. Flows exist only as metadata and do not refer to any external resource or asset. |
JOB |
A calculation or process that trac has or will orchestrate — for example, to execute calculation using a Model or Flow and some data inputs. |
FILE |
A discrete unit of digital information that is available on trac. Files can be used as job inputs, but trac cannot describe or assure the contents of a File. |
Note
‘Model schema’ refers to the set of schemas which describe a model’s inputs, outputs and parameters. This is not a separate object type, it’s part of the model object.
This diagram shows the interactions between different object types. See Virtual Deployment for more details.
Jobs¶
Users with appropriate permissions can configure and run five different job types.
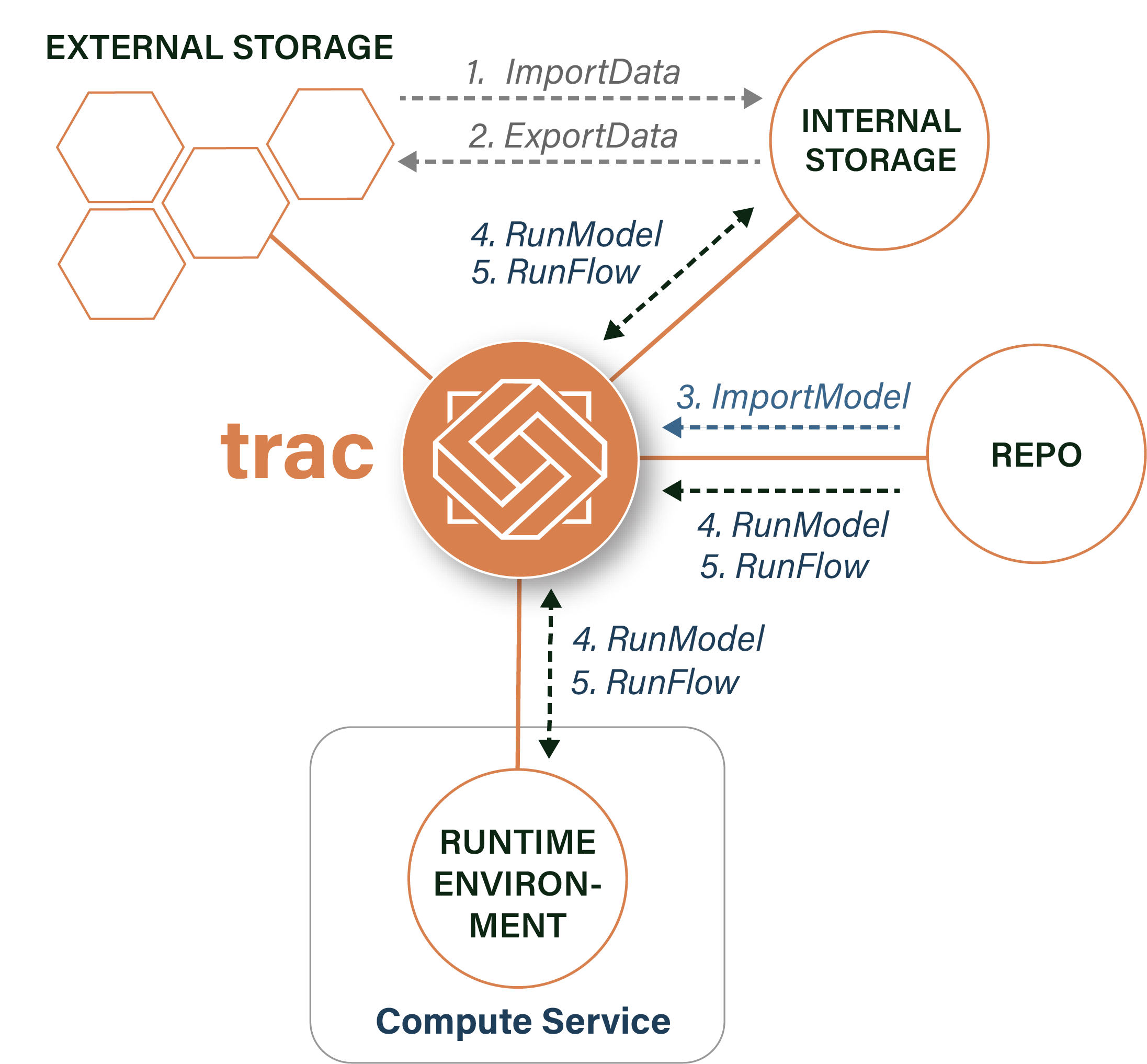
ImportData |
Copies data from an External Storage location into trac via a batch import process |
ExportData |
Publishes data from trac to an External Storage location via a batch import process |
ImportModel |
Imports a new model or model version from a Repository |
RunModel |
Runs a model against a set of data and parameter inputs, in a Runtime Environment |
RunFlow |
Runs a flow against a set of data, model and parameter inputs, in a Runtime Environment |
Note
Data, File and Schema objects can be loaded via the UI, which directly creates the object in the metadata store without a corresponding Job. This is also true for building and saving a Flow.
Virtual deployment¶
In trac, models are not deployed in the traditional sense - the code stays in the repository and is fetched dynamically at runtime.
IMPORT MODEL |
The model code is scanned by not copied. A new metadata object is created which contains the model schema and a link to the code commit in the repository |
BUILD FLOW |
Models are combined into execution processes where the outputs of one model become the inputs to the next. Flows exist only as trac metadata and are built from the model schemas, not the model code |
RUN FLOW |
To launch a Job you select the data inputs for that run based on schema validation. The model code is then fetched from the repository at runtime. |
Note
This short video (under 3 mins) explains the virtual deployment method.